12
ArchiveBox
🗃 Das selbst gehostete Open Source-Webarchiv.Nimmt Browserverlauf / Lesezeichen / Pocket / Pinnwand / etc. Auf, speichert HTML, JS, PDFs, Medien und mehr.
- Kostenlose
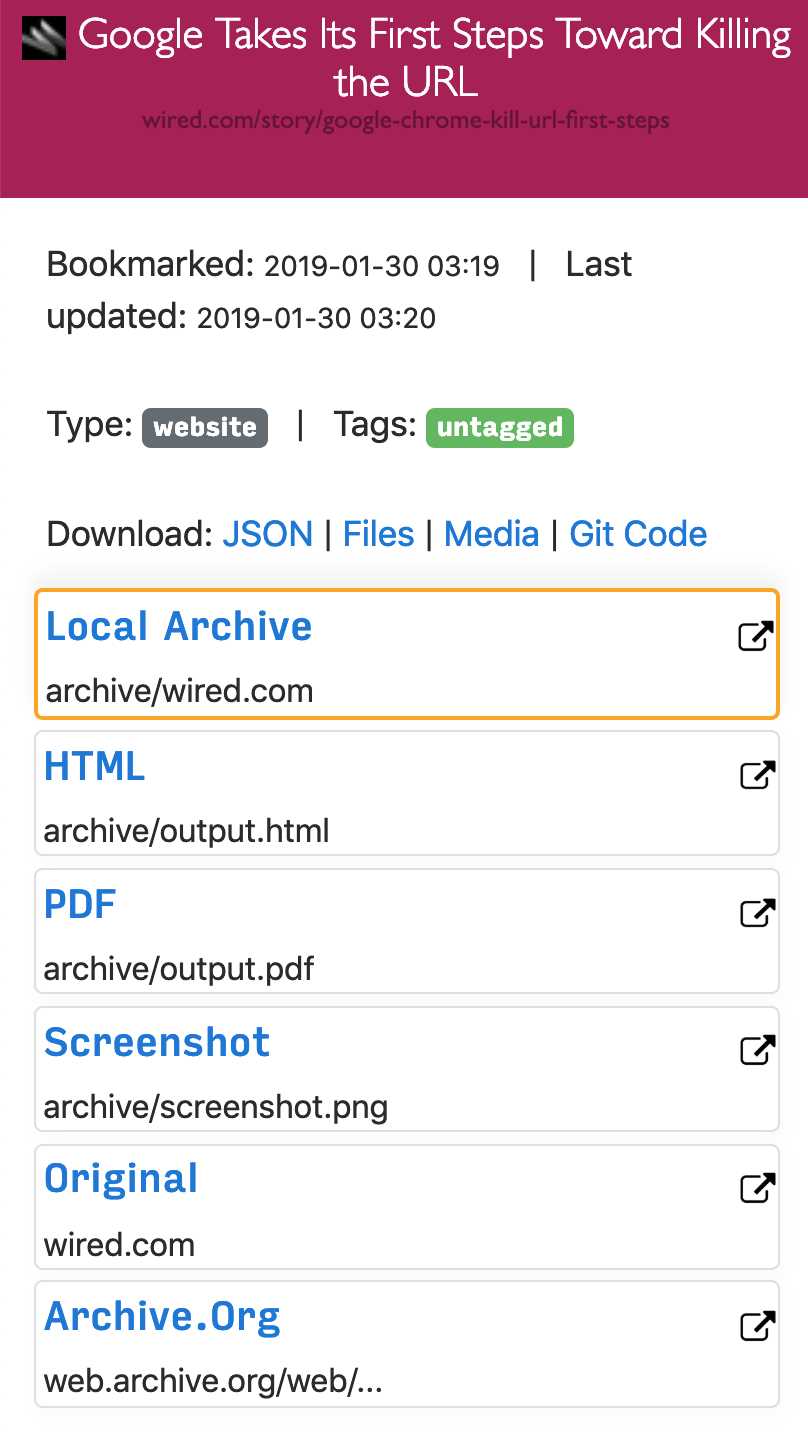
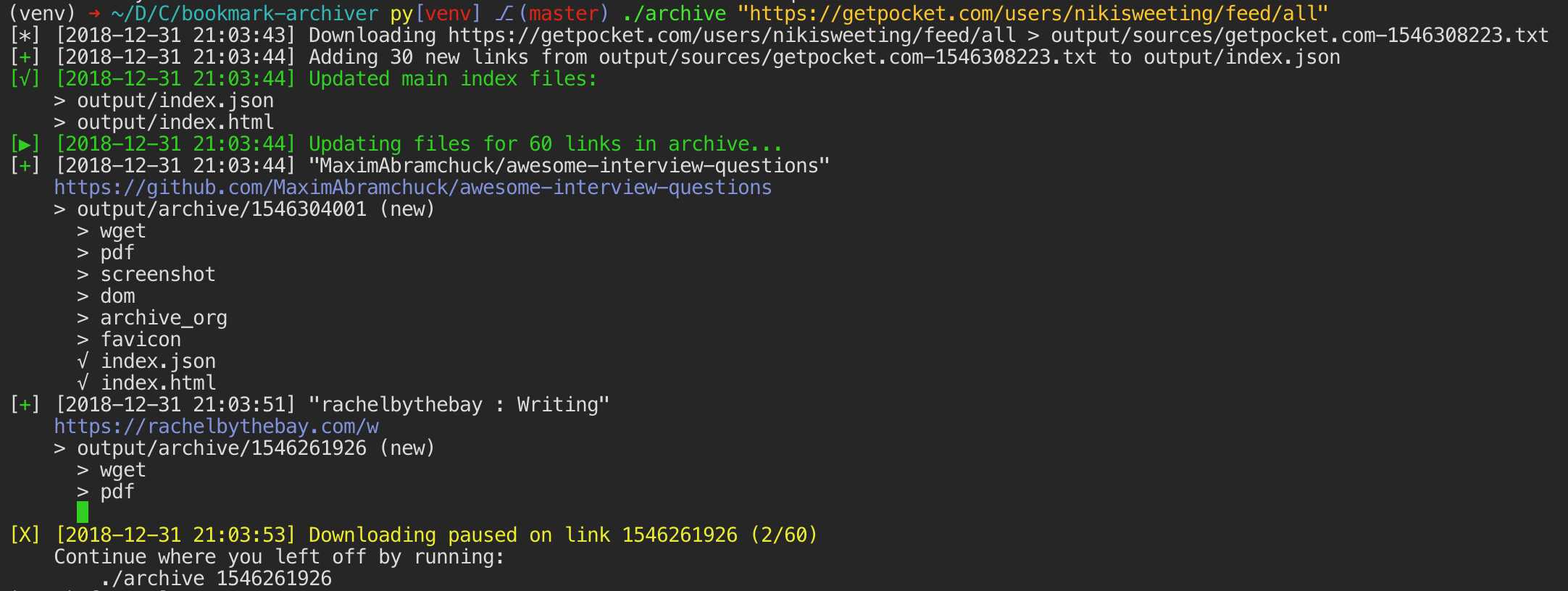
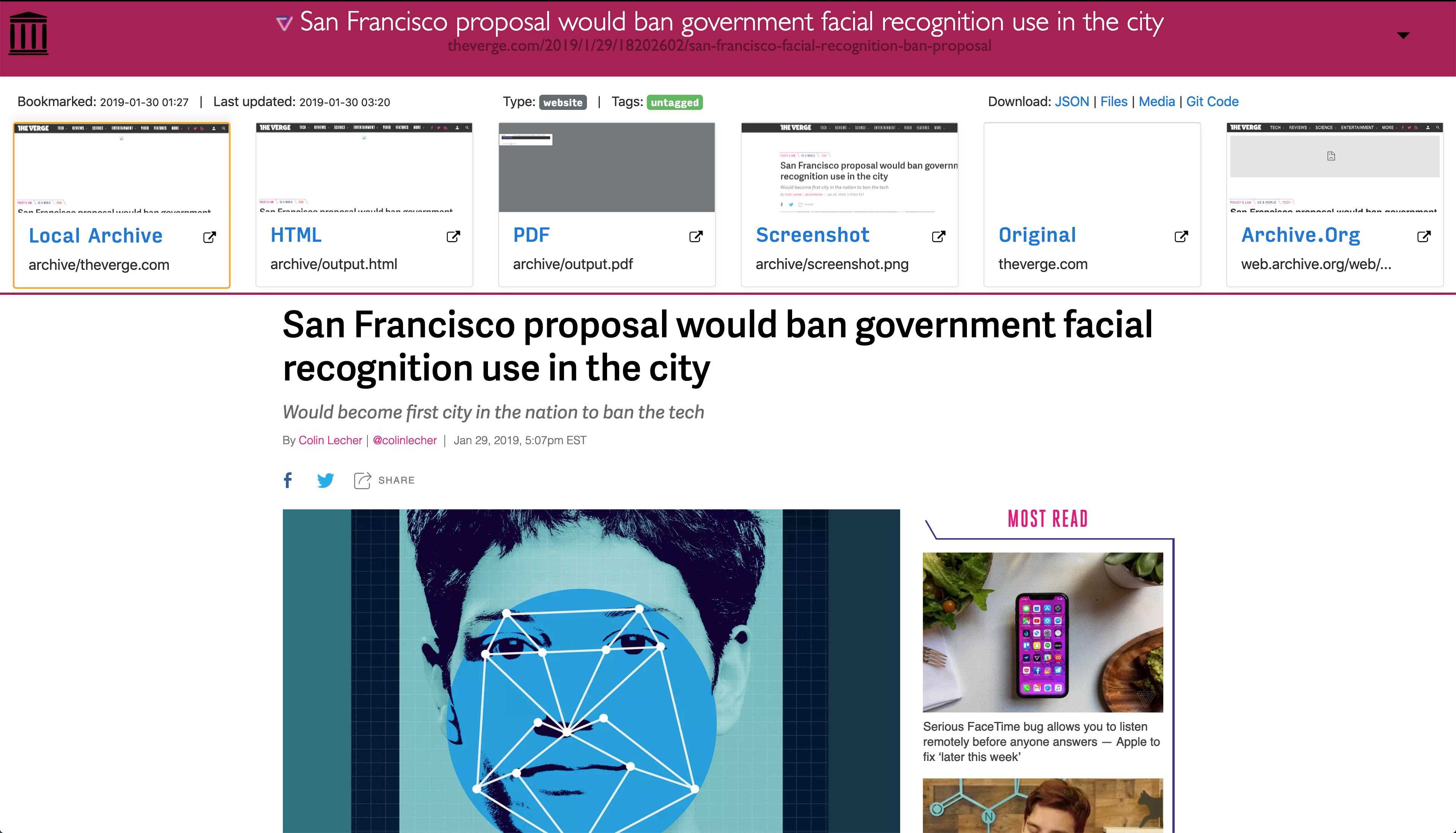
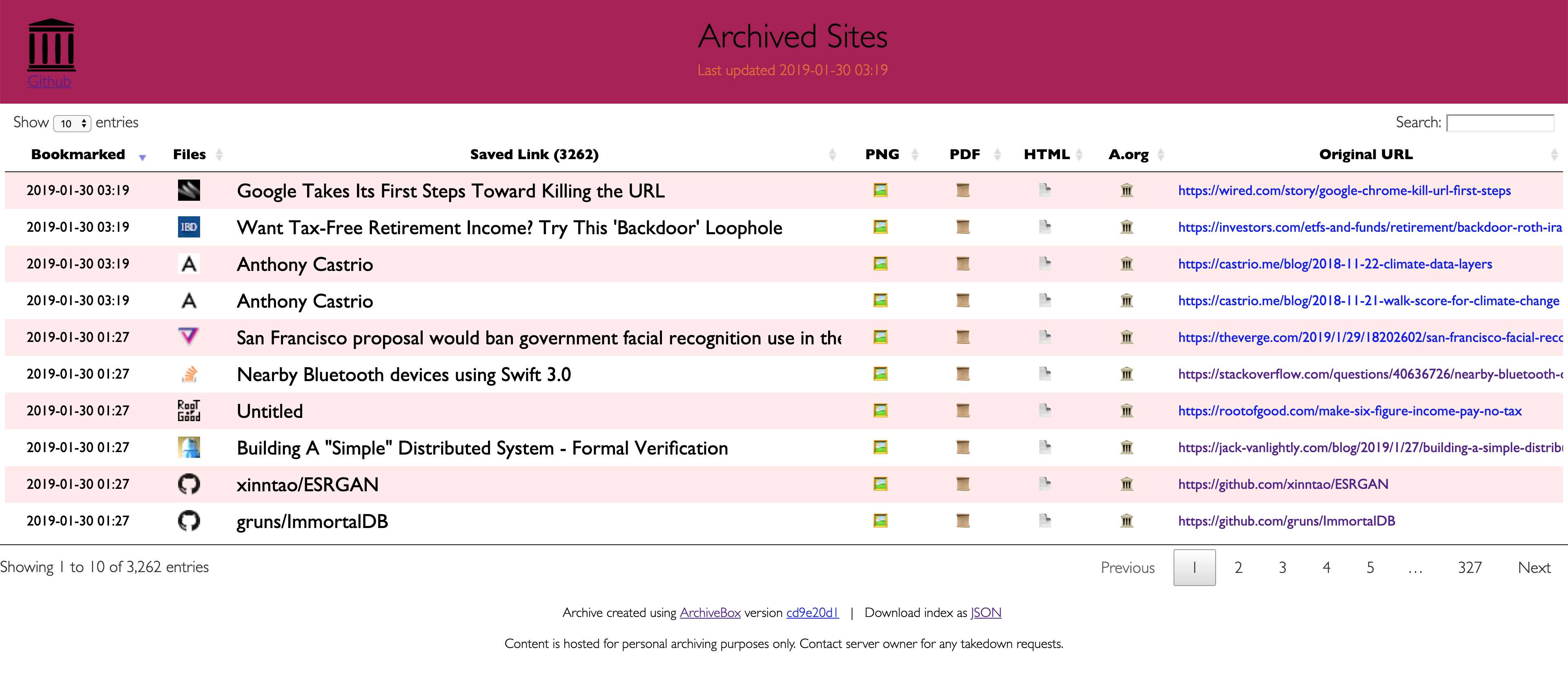
Da moderne Websites kompliziert sind und häufig auf dynamischen Inhalten beruhen, archiviert ArchiveBox die Websites in verschiedenen Formaten, die nicht nur von öffentlichen Archivierungsdiensten wie Archive.org und Archive.is gespeichert werden können.ArchiveBox importiert eine Liste von URLs aus stdin, remote url oder file und fügt die Seiten dann mithilfe von wget einem lokalen Archivordner hinzu, um einen durchsuchbaren HTML-Klon, YouTube-dl zum Extrahieren von Medien und eine vollständige Instanz von Chrome headless for PDF zu erstellen.Screenshots, DOM-Dumps und mehr ... Durch die Verwendung mehrerer Methoden und des marktbeherrschenden Browsers zur Ausführung von JS wird sichergestellt, dass wir selbst die komplexesten, kniffligsten Websites in mindestens einigen hochwertigen Langzeitdatenformaten speichern können.### Kann Links importieren von: - Pocket, Pinboard, Instapaper - RSS, XML, JSON oder Klartextlisten - Browserverlauf oder Lesezeichen (Chrome, Firefox, Safari, IE, Opera und mehr) - Shaarli, Delicious, RedditGespeicherte Posts, Wallabag, Unmark.it und jeder andere Text mit darin enthaltenen Links!### Kann diese Dinge für jede Site speichern: - `favicon.ico` favicon der Site -` example.com / page-name.html` wget Klon der Site, mit angehängter .html wenn nicht vorhanden - `Ausgabe.pdf` Gedrucktes PDF der Site mit kopflosem Chrom - `screenshot.png` 1440x900 Screenshot der Site mit kopflosem Chrom -` output.html` DOM Dump des HTML nach dem Rendern mit kopflosem Chrom - `archive.org.txt` Ein Link zurgespeicherte Seite auf archive.org - `warc /` für die HTML + Gzipped Warc Datei.gz - `media /` beliebige mp4, mp3, Untertitel und Metadaten, die mit youtube-dl gefunden wurden - `git /` Klon eines beliebigen Repositorys für github-, bitbucket- oder gitlab-Links - `index.html` &` index.json`HTML- und JSON-Indexdateien mit Metadaten und Details Die Archivierung ist additiv, sodass Sie die regelmäßige Ausführung von `. / Archive` einplanen und neue Links in den Index ziehen können.Der gesamte gespeicherte Inhalt ist statisch und mit JSON-Dateien indiziert, sodass er für immer lebt und leicht zu analysieren ist. Es ist kein ständig laufendes Backend erforderlich.
Kategorien
Alternativen zu ArchiveBox für alle Plattformen mit einer Lizenz
2
WebArchives
Ein Webarchiv-Viewer, mit dem Sie Millionen von Artikeln aus großen Community-Projekten wie Wikipedia oder Wikisource offline durchsuchen können.
1
Web Dumper
Laden Sie ganze Websites aus dem Internet herunter und speichern Sie sie auf Ihrer Festplatte ...